What Is Cohere AI?
Cohere AI is a technology company focusing on large language model (LLMs) technologies for enterprise use cases. It provides LLM-based solutions that help customers understand, generate, and work with human language. Through its services, organizations can automate customer support, generate content, and extract insights from large volumes of text.
Cohere AI’s technology is based on LLMs similar to those used in Google’s BERT or OpenAI’s GPT. Their models are trained on diverse datasets that encompass a range of language use, allowing them to perform various NLP tasks with high accuracy and context understanding. They can be easily fine tuned for specific use cases, and provide enterprise-grade capabilities including the ability to deploy the models on-premises.
This is part of a series of articles about LLM Platform.
Cohere Products and Models
Cohere offers three primary models: Command, Embed, and Rerank.
Related content: Read our guide to Aisera.
Cohere Command Models
Cohere’s Command models are designed to follow user instructions to generate relevant text, making them suitable for various conversational applications. The different versions of the Command models are:
- Command R+: The latest and most powerful version, released in April 2024. It is an instruction-following model that can handle complex text-based tasks with high reliability. It has a maximum context length of 128,000 tokens, making it useful for Retrieval-Augmented Generation (RAG) workflows and multi-step tool usage. This model is particularly suitable for scenarios requiring extensive context retention.
- Command R: Similar to Command R+, this model performs language tasks and supports complex workflows including code generation and RAG. It also has a context length of 128,000 tokens.
- Command: The original version of the model, providing instruction-following capabilities with a context length of 4,096 tokens.
- Command Light: A smaller, faster variant of the Command model with a context length of 4,096 tokens.
Note: Command and Command Light are legacy models, and Cohere recommends using the newer R and R+.
Cohere Embed Models
Cohere’s Embed models are specialized for generating text embeddings, which can be used to determine semantic similarity, classify text, or perform other analysis tasks. The key models include:
- Embed English v3.0: Creates high-quality embeddings for English text, supporting up to 512 tokens with a dimensionality of 1,024. It is designed for applications needing precise semantic similarity measurements using cosine similarity.
- Embed English Light v3.0: A faster, smaller version of Embed English v3.0 with 384 dimensions and 512 tokens. It balances performance and speed while still providing embeddings for English text.
- Embed Multilingual v3.0: Supports multiple languages and provides embeddings with a dimensionality of 1,024 for up to 512 tokens. It is useful for multilingual applications and supports cosine similarity for semantic comparison.
- Embed Multilingual Light v3.0: A smaller, faster variant of Embed Multilingual v3.0 with 384 dimensions and 512 tokens, offering a trade-off between speed and capability.
Cohere also offers its previous embedding model, Embed v2.0, with the same variants as above.
Cohere Rerank Models
Cohere’s Rerank models are used to reorder search results or document lists to improve relevance based on specific criteria. It is primarily used for semantic search use cases. The main models include:
- Rerank English v3.0: Designed for re-ranking English language documents and semi-structured data like JSON. It supports a context length of 4,096 tokens, making it suitable for enhancing search algorithms and document organization.
- Rerank Multilingual v3.0: Supports re-ranking for documents and semi-structured data in multiple languages, with the same context length of 4,096 tokens. It is compatible with the languages supported by Embed Multilingual v3.0.
Cohere also offers its previous embedding model, Rerank v2.0, with the same variants as above.
Cohere Pricing
Cohere offers three pricing tiers:
- Free Tier: Provides rate-limited usage for learning and prototyping. It includes access to all endpoints, ticket support, and help via the Cohere Discord community. Usage is free until you go into production.
-
Production Tier: Aimed at businesses ready to deploy hosted language models. Features include training custom models, elevated ticket support, access to all endpoints, and increased rate limits. Pricing is based on input and output tokens:
- Command R+: $3.00 per million input tokens and $15.00 per million output tokens.
- Command R: $0.50 per million input tokens and $1.50 per million output tokens.
- Command R (fine-tuned): $2.00 per million input tokens, $4.00 per million output tokens, and $8.00 per million training tokens.
- Enterprise Tier: This tier is for customers needing dedicated model instances, dedicated support channels, or custom deployment options. Pricing details are not publicly available.
What Is the Cohere Toolkit?
The Cohere Toolkit is a collection of pre-built components designed to streamline the development and deployment of retrieval augmented generation (RAG) applications. It reduces the time needed to bring RAG solutions to market, allowing developers to go from concept to deployment in a few minutes.
The Toolkit is divided into two main components:
- Front-end: A web application built using Next.js. It comes with a built-in SQL database that stores conversation history, documents, and citations, making it easy to manage and retrieve data directly within the application.
- Back-end: Includes preconfigured data sources and retrieval code necessary for setting up RAG with custom data sources, known as retrieval chains. Users can choose which model to use, selecting from Cohere’s models hosted on their native platform, Azure, or AWS Sagemaker. By default, the Toolkit is set up with a LangChain data retriever to test RAG capabilities on Wikipedia and user-uploaded documents.
Here’s an image that shows how these different components work together:
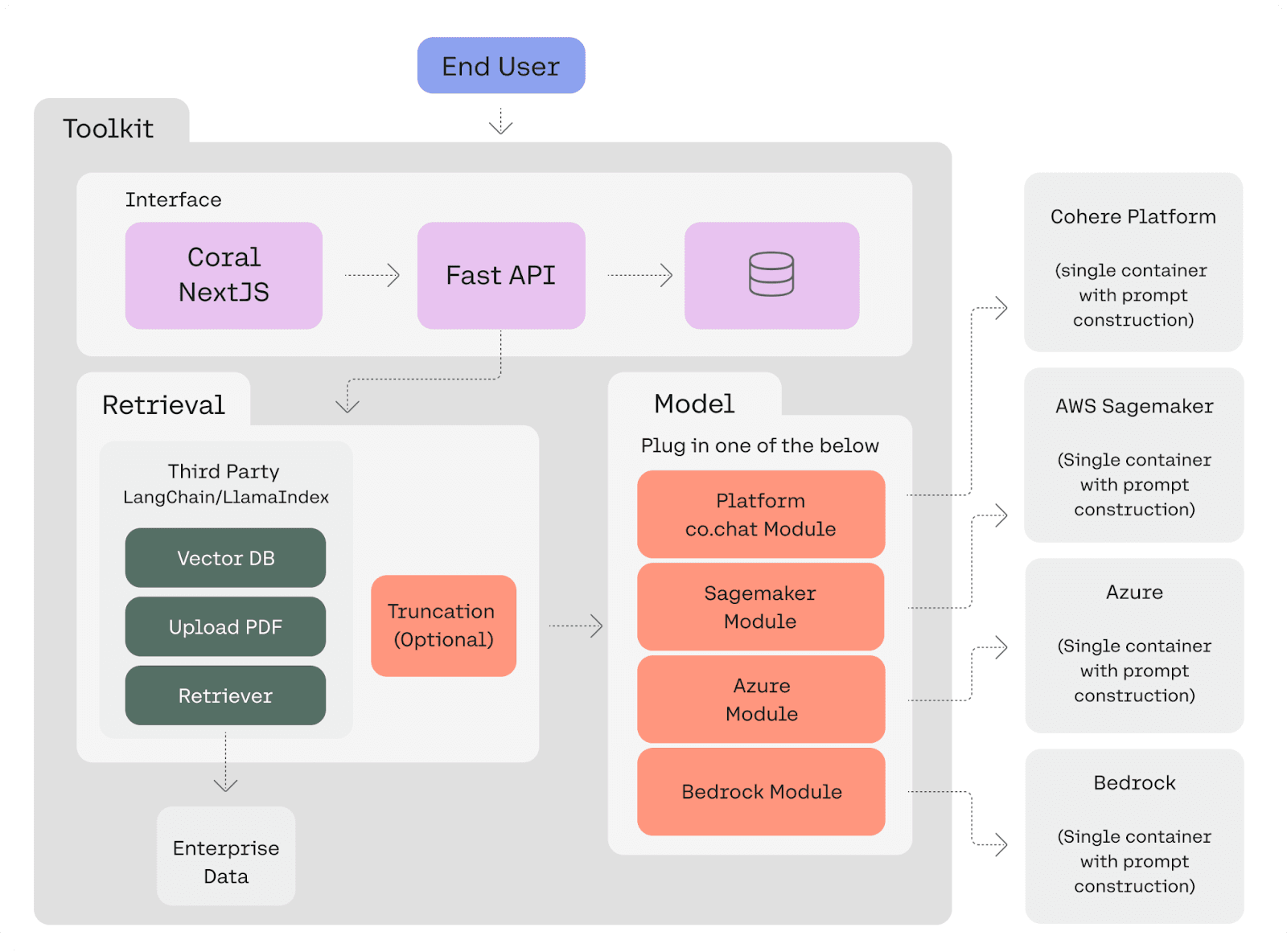
Source: Cohere
{kind=link}
Tutorial: Using the Cohere Chat API
The Cohere Chat API allows developers to interact with Cohere’s language models via a conversational interface. This tutorial will guide you through setting up and using the Chat API with code examples in Python. The code in this tutorial is adapted from the Cohere documentation.
Setup {#setup}
To use the Chat API, you need to have a Cohere account and an API key. You can install the Cohere Python client using pip install cohere (or in Python 3). pip3 install cohere
Basic Usage
Here’s how to generate text using the Chat API. This example demonstrates how to prompt the model to create a blog post title about API design.
import cohere
# Start the Cohere client using the API key
co = cohere.Client(api_key="<MY API KEY>")
# Send the model a message to retrieve a response
response = co.chat(
model="command-r-plus",
message="Generate a title for an article about web design. Output only the title text."
)
# Print out the generated text
print(response.text)
The expected output should be something like this:

The Response Structure
A typical response from the Chat API includes several fields:
{
"text": "The Science of Web Design: How to Build an Engaging Web Page",
"generation_id": "dd84b9fc-928d-4e17-4819-8ffde9366947",
"chat_history": [
{
"role": "USER",
"message": "Generate a title for an article about web design. Output only the title text."
},
{
"role": "CHATBOT",
"message": "The Science of Web Design: How to Build an Engaging Web Page"
}
],
"finish_reason": "COMPLETE",
"meta": {
"api_version": {
"version": "1"
},
"billed_units": {
"input_tokens": 16,
"output_tokens": 14
},
"tokens": {
"input_tokens": 16,
"output_tokens": 14
}
}
}
Key fields include:
- text: The generated message from the model.
- generation_id: An ID for the response.
- chat_history: Logs the conversation.
- finish_reason: Indicates why the model stopped generating text (e.g., "COMPLETE").
- meta: Contains metadata like token counts and billing information.
Multi-Turn Conversations {#multi-turn-conversations}
You can maintain a conversation by including the chat_history parameter. Here’s an example:
import cohere
co = cohere.Client(api_key="<MY API KEY>")
# The original user message
message = "What are generative models?"
# Send a message alongside the chat history
response = co.chat(
model="command-r-plus",
chat_history=[
{"role": "USER", "text": "Hello, my name is George!"},
{"role": "CHATBOT", "text": "Hello George! How can I help you?"},
],
message=message
)
print(response.text)
The response should look like this:
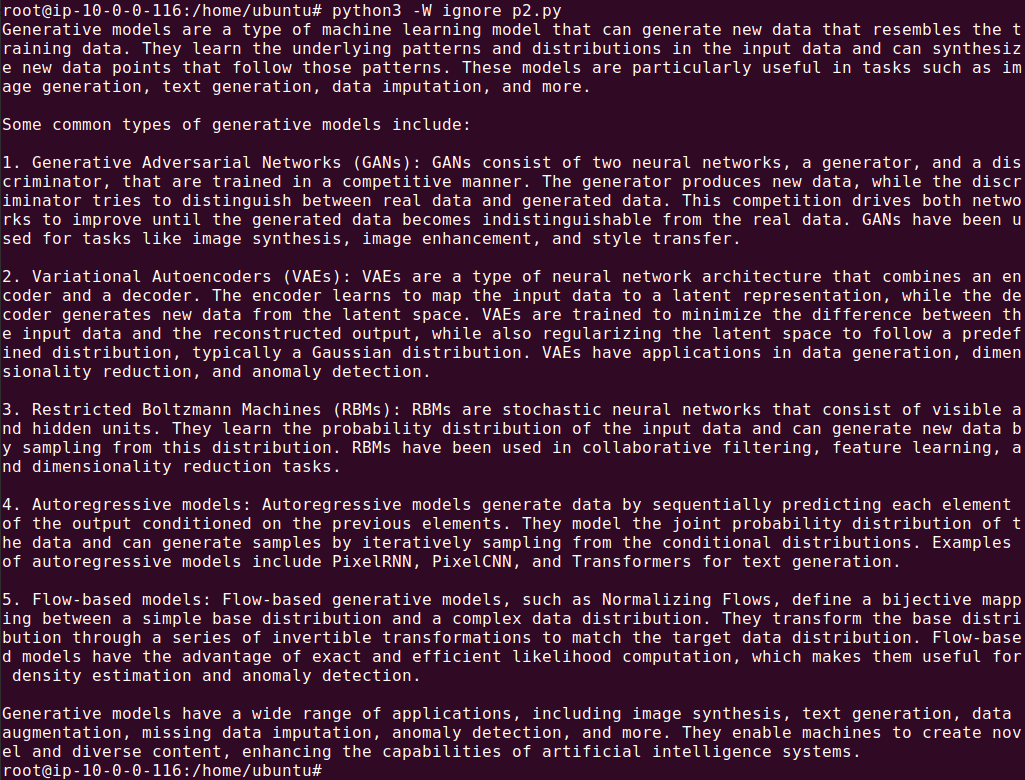
Dynamic Chat History {#dynamic-chat-history}
You can build the chat history dynamically during a conversation. Here’s a script that interacts with the user for multiple turns:
import cohere
co = cohere.Client(api_key="<MY API KEY>")
chat_history = []
max_turns = 10
for _ in range(max_turns):
# Get the user input
message = input("Send a message to the model: ")
# Generate the response using the chat history
response = co.chat(
message=message,
temperature=0.3,
chat_history=chat_history
)
answer = response.text
print(answer)
# Add a message and an answer to the chat history
user_message = {"role": "USER", "text": message}
bot_message = {"role": "CHATBOT", "text": answer}
chat_history.append(user_message)
chat_history.append(bot_message)
The response should look like this:
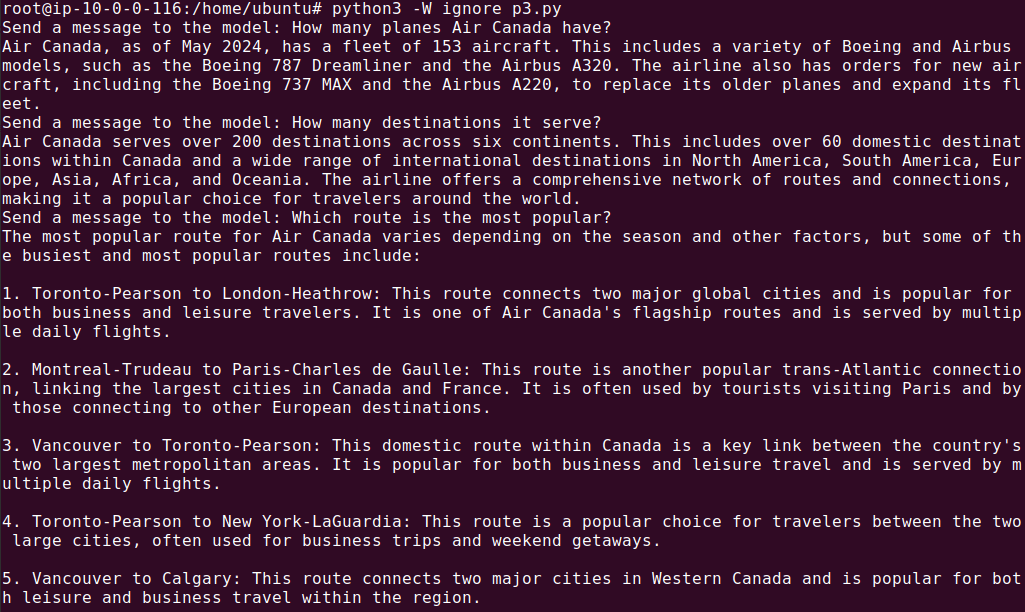
Saving the Chat History with a Conversation ID
An alternative to passing the full chat history is to use a conversation_id which allows the model to remember previous interactions without sending the history each time:
import cohere
co = cohere.Client(api_key="<YOUR API KEY>")
# Initiate a conversation with the user-defined ID
response = co.chat(
model="command-r-plus",
message="The secret number is 'three', remember this.",
conversation_id='user_defined_id_1',
)
print(response.text)
# Use the same ID to continue the conversation
response2 = co.chat(
model="command-r-plus",
message="What is the secret number?",
conversation_id='user_defined_id_1'
)
print(response2.text) # "The secret number is 'three'"
The output should look like this:

Note thatconversation_idand chat_history should not be used together as they serve the same purpose.
Note: To get cleaner output, add the -W ignore flag to ignore warnings.
Building LLM Applications with Cohere and Acorn
To download GPTScript visit https://gptscript.ai. As we expand on the capabilities with GPTScript, we are also expanding our list of tools. With these tools, you can build any application imaginable: check out tools.gptscript.ai and start building today.