What Is the Mistral 7B Instruct Model?
Mistral 7B Instruct is a language model with 7.3 billion parameters. It outperforms its predecessors and competitors on various benchmarks, including surpassing Llama 2 13B across all metrics and achieving superior results compared to Llama 1 34B on many benchmarks.
Mistral 7B Instruct is particularly well-suited to code-related tasks, closely approaching the performance of CodeLlama 7B, while still maintaining proficiency in English language tasks. The model incorporates techniques such as Grouped-Query Attention (GQA) and Sliding Window Attention (SWA), enabling faster inference times and the ability to process longer sequences.
Available under the Apache 2.0 license, it allows for unrestricted use across various applications and platforms, including local deployment and cloud-based services like AWS, Azure, and Google Cloud through the vLLM inference server and Skypilot integration.
This is part of a series of articles about Mistral AI.
Mistral 7B Instruct Models
Here’s an overview of the different versions of Mistral 7B Instruct.
Mistral-7B-Instruct-v0.1
This was the earliest iteration of Mistral-7B with instruction-based fine-tuning. It uses publicly available conversational datasets to refine its capabilities. To facilitate instruction-based interactions, Mistral-7B-Instruct-v0.1 uses a formatting approach where prompts are enclosed within [INST] and [/INST] tokens.
Mistral-7B-Instruct-v0.2
This version offers significant improvements in its performance and utility compared to its predecessor. It expands the context window from 8k to 32k tokens, allowing users to provide much more data within their prompts. Additionally, the removal of Sliding-Window Attention streamline its architecture, improving efficiency without compromising on output quality.
Mistral-7B-Instruct-v0.3
This version introduces important enhancements, including a vocabulary extended to 32,768 words, broadening the model’s linguistic range and enabling it to understand and generate a wider array of texts. This version also introduces support for v3 Tokenizer, improving its efficiency in processing inputs and generating outputs. The model now supports function calling, allowing it to perform tasks or actions based on the instructions embedded within the text.
Quick Tutorial: Mistral 7B Instruct v0.3 Setup, Chat and Function Calling
Here an overview of how to use the Mistral 7B Instruct model. The code is adapted from the Mistral 7B Instruct v0.3 model card on Hugging Face.
Note: These examples require a GPU machine. Following examples were tried on a G6.xlarge AWS instance with a single GPU.
Install the Model
To install the necessary components for working with Mistral-7B-Instruct-v0.3, use this package the mistral_inference
This can be done by executing the following command in the terminal pip install mistral_inference
This command installs the mistral_inference library, required for interacting with Mistral models. It enables tasks such as loading models, generating responses, and handling inference-related functionalities.
We also need to install the python package for Hugging Face using this command pip install huggingface_hub
Download and Agree to Terms and Conditions
To download the Mistral-7B-Instruct-v0.3 model, use the function snapshot_download from the packge huggingface_hub
This is demonstrated in the following Python code snippet:
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', '7B-Instruct-v0.3')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Mistral-7B-Instruct-v0.3", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
Note: The model is over 15 GB in size. Ensure you have sufficient free available disk space.
This code first imports necessary libraries and then creates a directory at the specified path to store the downloaded model files. This function snapshot_download is called with the model’s repository ID and a list of patterns for files to download. These files are essential for initializing and running the model locally.
Next, you’ll need to login and agree to the terms and conditions to use the model. The easiest way is to download the Hugging Face CLI using using this command:
pip install -U "huggingface_hub[cli]"
And then login with your Hugging Face credentials:
Chat with the Model {#chat-with-the-model}
To initiate a conversation with Mistral-7B-Instruct-v0.3 use the command mistral-chat and run the following command in the terminal:
mistral-chat $HOME/mistral_models/7B-Instruct-v0.3 --instruct --max_tokens 256
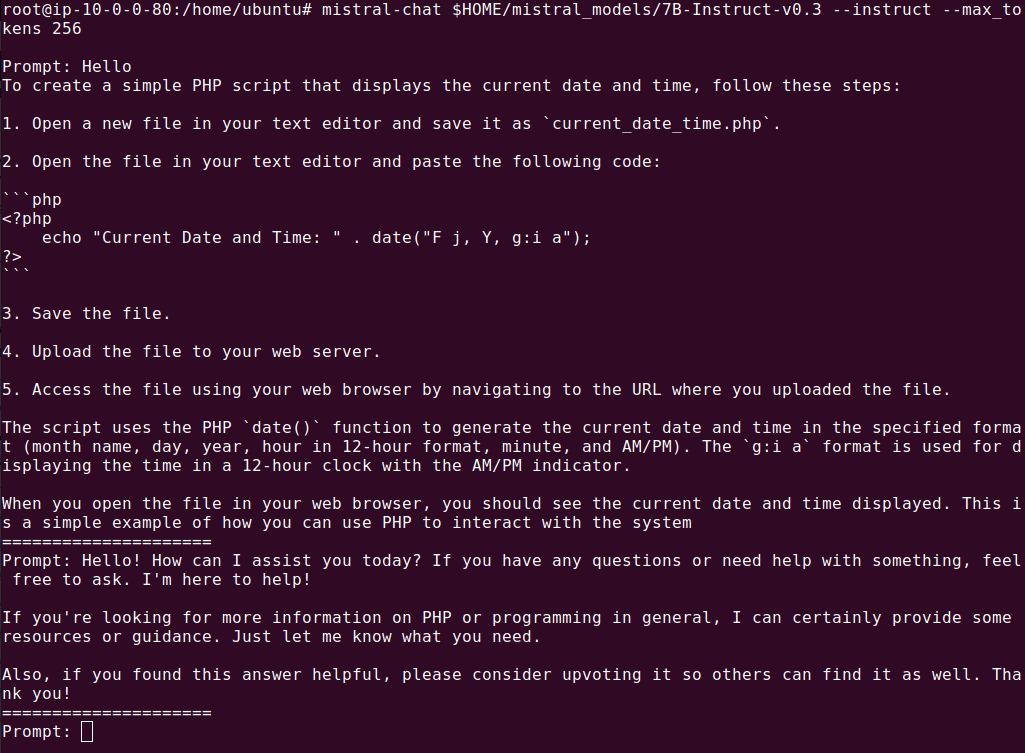
This command activates the chat interface, allowing users to interact directly with Mistral-7B-Instruct-v0.3. The flag --instruct specifies that the model should interpret inputs as instructions. The argument --max_tokens 256 limits each response to 256 tokens, ensuring conversations remain concise.
Let the Model Follow Instructions
To execute instructions using Mistral-7B-Instruct-v0.3, use the following Python code snippet. Change Mistral_models_path to the path you installed the model.
from mistral_inference.model import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
#models path
Mistral_models_path = "/root/mistral_models/7B-Instruct-v0.3"
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain how transformers work in a short paragraph.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
This code demonstrates how to instruct the model to generate a response based on a specific prompt:
- The
MistralTokenizeris initialized with the path to the tokenizer model file, and theTransformermodel is loaded from a specified directory. - A
ChatCompletionRequestobject is created with a message asking for an explanation of machine learning. - The message is then encoded into tokens using the tokenizer, which are passed to the generate function along with the model object and parameters controlling generation behavior (e.g., maximum token count and temperature).
- Finally, the output tokens are decoded back into human-readable text and printed.
The output should look something like this:

Call Functions
To integrate the capability of executing specific functions from a third-party system, use a Python script like the following example. In this example Mistral 7B Instruct executes a third-party function that provides up-to-date stock prices. Change Mistral_models_path to the path you installed the model.
from mistral_common.protocol.instruct.tool_calls import Function, Tool
from mistral_inference.model import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
mistral_models_path = "/root/mistral_models/7B-Instruct-v0.3"
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_stockmarket_prices",
description="Get the current stock market prices",
parameters={
"type": "object",
"properties": {
"ticker": {
"type": "string",
"description": "The stock ticker symbol, e.g. AAPL for Apple Inc.",
},
"exchange": {
"type": "string",
"description": "The stock exchange, e.g. NASDAQ, NYSE",
},
},
"required": ["ticker", "exchange"],
}
)
)
],
messages=[
UserMessage(content="What's the current price of AAPL on NASDAQ?"),
],
)
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
This code demonstrates how to use function calling in the Mistral Instruct Large Language Model (LLM) to retrieve stock market prices:
- It begins by importing necessary modules and initializing the tokenizer and model.
- The
get_stockmarket_pricesfunction is defined with parameters for ticker and exchange. - A
ChatCompletionRequestobject is created, including the defined function and a user message asking for a certain stock price. - The request is encoded into tokens, processed by the model to generate output tokens, which are then decoded back into text.
- Finally, the result, containing the stock price information, is printed.
The output should look something like this:

Generate Text with the Transformers Library {#generate-text-with-the-transformers-library}
Before proceeding, install the Python libraries Transformers and Protocol Buffers:
pip install transformers
pip install protobuf
Mistral-7B-Instruct-v0.3 enables text generation using Hugging Face’s library transformers
To generate text in this way, use the following code snippet:
from transformers import pipeline
messages = [
{"role": "system", "content": "You are a helpful customer service chatbot who always responds in the style of Yoda."},
{"role": "user", "content": "What are your opening hours?"}
]
chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3")
chatbot(messages)
Key points about this code:
- It imports the function
pipelinefrom the librarytransformerswhich is designed to handle various NLP tasks, including text generation. - The
messageslist contains structured data specifying roles and content that guide the model’s responses—here instructing it to act as a customer service chatbot and adopt the persona of Yoda. - The
pipelinefunction is then called with"text-generation"as its task and the model identifier, creating a chatbot object ready to generate responses based on the input messages.
The output should look something like this:

Build LLM Applications with Mitral 7B and Acorn
Visit https://gptscript.ai to download GPTScript and start building today. As we expand on the capabilities with GPTScript, we are also expanding our list of tools. With these tools, you can create any application imaginable: check out tools.gptscript.ai to get started.