What Is the Open LLM Leaderboard?
The Open LLM Leaderboard, hosted on Hugging Face, evaluates and ranks open-source Large Language Models (LLMs) and chatbots. It serves as a resource for the AI community, offering an up-to-date, benchmark comparison of various open-source LLMs. This platform enables the submission of models for automated evaluation, ensuring standardized and impartial assessment of each model’s capabilities.
This leaderboard is part of The Big Benchmarks Collection on Hugging Face, which encompasses a broader set of benchmarks such as MTEB and LLM-Perf. These benchmarks help compare strengths and weaknesses of different models across varied tasks and scenarios.
The Open LLM Leaderboard ranks models on several benchmarks including ARC, HellaSwag and MMLU, and makes it possible to filter models by type, precision, architecture, and other options. We explain all these options in more detail below.
You can access the Open LLM Leaderboard here.
Related content: Read our guide to LLM leaderboards.
Image credit: Hugging Face
This is part of a series of articles about best LLM.
How the Open LLM Leaderboard Evaluates LLMs
The Open LLM Leaderboard evaluates Large Language Models through a rigorous, automated process that ensures fairness and reliability. Models submitted to the leaderboard undergo evaluation on a standardized GPU cluster, which guarantees consistent performance measurement across different submissions.
By using a uniform testing environment, the leaderboard levels the playing field, making it possible to accurately gauge the strengths and limitations of each model based on their performance metrics.
Evaluation criteria cover a range of capabilities, including natural language understanding, content generation, coding, and reasoning. The process involves running each model through multiple tasks and scenarios that are reflective of real-world applications and challenges. Results from these evaluations are then compiled and presented on the leaderboard.
6 Key Benchmarks Used by the Open LLM Leaderboard
Let’s review the main benchmarks used to evaluate models in the Open LLM Leaderboard.
ARC
The AI2 Reasoning Challenge (ARC), developed by Clark et al. (2018), evaluates the question-answering capabilities of LLMs. It comprises 7,787 multiple-choice science questions derived from 3rd to 9th-grade level exams, segmented into an “Easy Set” and a more challenging “Challenge Set”.
The Challenge Set is designed to test models beyond fact retrieval, requiring complex reasoning to answer questions correctly. This measures a model’s depth of understanding and its ability to apply knowledge in solving intricate problems. ARC’s structure allows assessment of an LLM’s reasoning skills, useful for complex science questions.
HellaSwag
HellaSwag challenges LLMs on their common-sense reasoning and understanding of physical scenarios. It presents models with scenarios where they must choose the most plausible continuation.
The benchmark uses adversarial filtering to craft questions, selecting incorrect answers designed to be particularly challenging for models that rely heavily on statistical patterns rather than genuine comprehension. This approach ensures that only LLMs with superior reasoning capabilities can achieve high scores.
MMLU
The Massive Multitask Language Understanding (MMLU) benchmark is designed to evaluate LLMs across a range of language understanding tasks. It encompasses subjects ranging from humanities to natural sciences, assessing the model’s versatility and depth in various domains. This coverage ensures that models can perform consistently across different language tasks.
MMLU can simulate real-world applications where the context and subject matter vary significantly. It challenges models to demonstrate their learning efficiency and adaptability by requiring them to apply knowledge from one domain to another. This cross-domain evaluation helps in developing LLMs for dynamic environments.
TruthfulQA
TruthfulQA assesses the accuracy and reliability of responses provided by LLMs. It focuses on the truthfulness of an LLM’s answers, presenting models with questions that require the ability to discern and convey accurate information. It is relevant for contexts where misinformation can have significant consequences, helping evaluate the trustworthiness of AI-generated content.
This benchmark helps ensure that LLMs adhere to factual correctness over generating plausible yet potentially misleading responses. High scores on this benchmark reflect a model’s proficiency in verifying facts.
Winogrande
Winogrande assesses LLMs on their ability to solve pronoun disambiguation problems. It presents models with sentences where they must correctly determine the referent of a pronoun, a task that requires an advanced grasp of linguistic nuances and the ability to infer relationships between entities in text.
This benchmark is inspired by the Winograd Schema Challenge, designed to be particularly challenging for AI by requiring more than surface-level text analysis. High performance on Winogrande indicates an LLM’s understanding of language structure and its capacity to interpret context correctly.
GSM8K
GSM8K evaluates LLMs on their ability to solve grade-school math problems, encompassing basic to intermediate mathematical operations. This set includes 8,500 questions designed to test the models’ computational and logical reasoning capabilities by requiring them to work through multi-step problems.
This benchmark assesses numerical reasoning, applicable in educational contexts. High scores indicate a model’s effectiveness in understanding and solving mathematical problems, which could be useful for educational support tools and learning enhancement.
Understanding Types of LLMs in the Open LLM Leaderboard
You can filter the long list of models in the Open LLM Leaderboard according to types. Let’s review the available model types.
Pretrained Models
Pretrained models are trained on vast datasets encompassing a range of topics, text types, and languages. This extensive training process equips them with a broad understanding of language patterns, structures, and nuances. These models serve as a versatile base for further specialization through additional training processes.
Pretrained models can generalize across different tasks without specific tuning, making them useful for various natural language processing applications. They enable developers to bypass the time-consuming and resource-intensive phase of initial model training.
Fine-Tuned Models
Fine-tuned models undergo additional training beyond their initial pretraining phase. This involves adjusting the model on a smaller, more specific dataset related to a particular task or domain. The fine-tuning phase allows these models to specialize, enhancing their performance on tasks such as sentiment analysis, document summarization, or question-answering in specific fields.
By building upon the broad knowledge base acquired during pretraining, fine-tuned models achieve higher accuracy and relevance in their outputs for targeted applications. They tailor general-purpose LLMs to niche requirements with relatively minimal additional training time and computational resources.
Instruction-Tuned Models
Instruction-tuned models are optimized to understand and execute task-based instructions. This involves training the model on datasets consisting of various tasks and their corresponding instructions, enabling the model to better parse and respond to directives. The goal is to enhance the model’s ability to comprehend and act upon complex instructions.
These models can be directly applied in user-driven scenarios, which require precise execution of tasks based on instructions. They can understand nuanced commands and produce relevant, context-aware responses.
RL-Tuned Models
RL-tuned models have undergone reinforcement learning fine-tuning. This process involves refining the model’s responses based on feedback from a reward system, simulating a learning environment where the model is encouraged to make decisions that lead to better outcomes.
The models learn to optimize their performance for specific goals or metrics, such as generating more engaging text or providing more accurate answers. The reinforcement learning allows them to dynamically adjust their strategies based on the success of previous interactions, making them effective for tasks requiring nuanced understanding and adaptation.
Types of Model Precision in the Open LLM Leaderboard
The Open LLM Leaderboard categorizes models by their precision, for example bfloat16 or 4bit. Let’s understand what the different precision values mean.
float16
The float16 format, also known as half-precision floating-point, is used to manage memory usage and computational requirements. Occupying only 16 bits of computer memory, float16 allows for the reduction of the size and computational overheads of LLMs. This format is useful for hardware that supports half-precision arithmetic, speeding up operations like model training and inference.
However, the use of float16 may introduce challenges such as decreased numerical stability and a potential reduction in model accuracy due to its limited precision compared to higher bit formats.
bfloat16
The bfloat16 format is a truncated version of the traditional 32-bit floating-point representation, designed to maintain a wide dynamic range while reducing the precision of the argument. This balance between range and precision makes it suitable for neural network applications, including LLMs.
By retaining the 8-bit exponent of a standard float but cutting the argument to 16 bits, bfloat16 allows for nearly equivalent model training and inference performance as with full precision, but with half the data bandwidth and storage requirements. This efficiency supports faster computations and the deployment of more complex models or larger batches during training.
8bit and 4bit Quantization
8bit and 4bit quantization techniques are strategies employed to compress LLMs by reducing the precision of the model’s weights from their original floating-point representations. This decreases the memory footprint and speeds up computation, making it feasible to deploy more sophisticated models on devices with limited computational resources.
While 8bit quantization is commonly used for its balance between performance and accuracy, 4bit quantization significantly reduces the model size at the risk of greater accuracy loss. These methods are useful for applying advanced LLMs in resource-constrained environments.
GPTQ
Gradient-Partitioned Training Quantization (GPTQ) is a specialized method designed for optimizing the efficiency of GPT models, with a focus on enhancing GPU inference performance. It lowers the precision of a model’s weights while striving to preserve its original performance levels.
GPTQ is a post-training quantization technique, meaning it is applied after the model has been fully trained. This allows for significant reductions in the model’s size and computational demands without requiring changes to the initial training process. GPTQ enables more efficient storage and execution of large models, making AI applications more accessible.
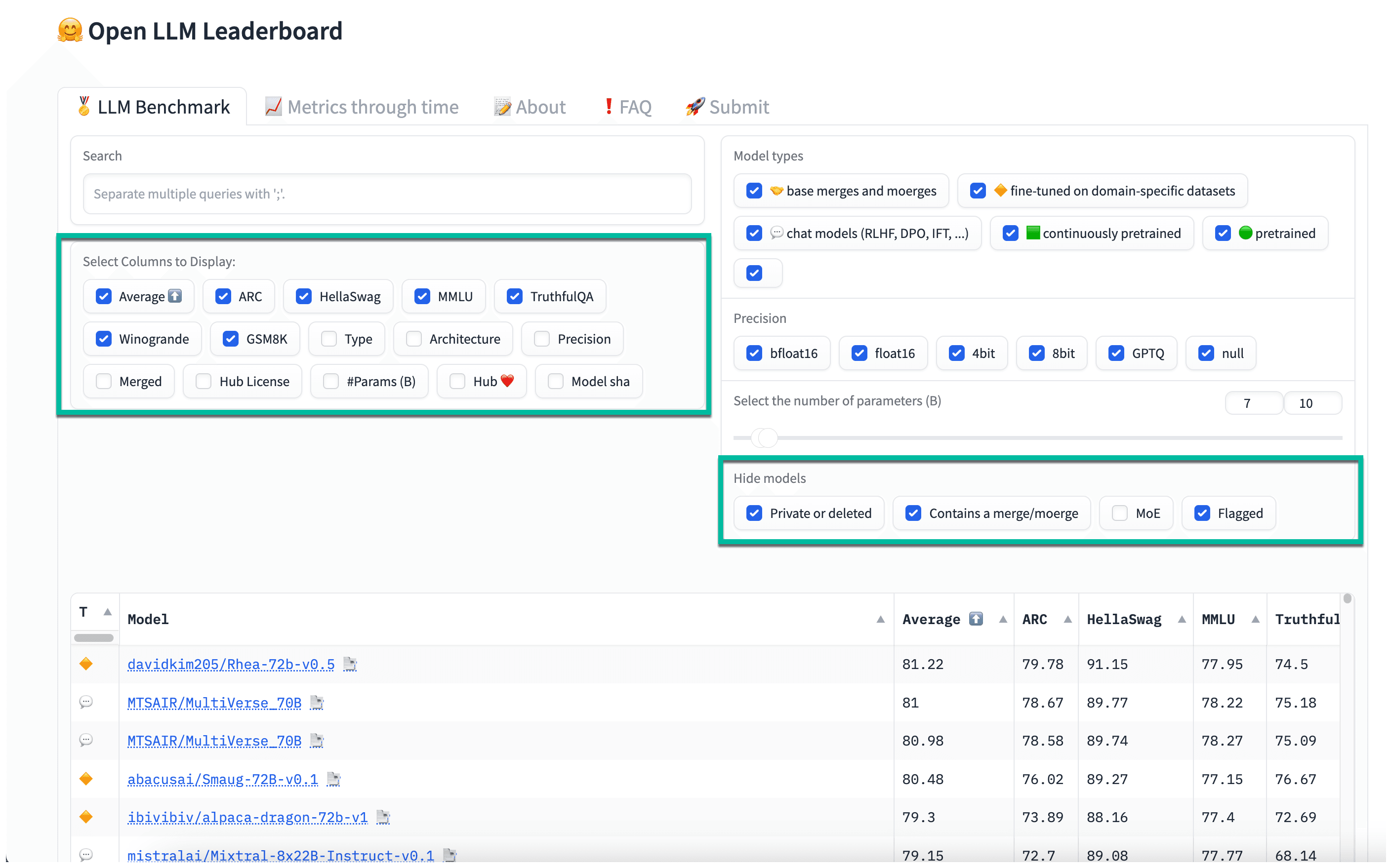
Other Filter Options in the Open LLM Leaderboard
Here are some of the other filters that can be used to evaluate the LLMs on the leaderboard:
- Architecture: Describes the architecture used to build the LLM
- Merged: Indicates whether this model variant is a combination of several models
- Hub License: License under which the model is released (some licenses might not allow commercial use)
- Available on the Hub: Whether the model is available to access on the Hugging Face Hub
- Model SHA: The Secure Hash Algorithm signature that identifies the model
- Flagged: Indicates if the model has been flagged due to concerns by users or moderators
Building Applications with Open LLMs and Acorn
Visit https://gptscript.ai to download GPTScript and start building today. As we expand on the capabilities with GPTScript, we are also expanding our list of tools. With these tools, you can create any application imaginable: check out tools.gptscript.ai to get started.